

20 年以上开发经验。完成了包括 SIP 软交换系统、电信计费系统、ERP/HRMS 平台、职业精平台、智能 IoT 货架等在内的多款产品。参与淘宝网和上海银基联合创建的云计算平台(阿里云前身)架构设计,并负责实现其中的几个关键组件。曾作为技术顾问参与上海地铁一号线改造工程。
拥有数十项国家和国际发明专利及软件产品著作权等知识产权。擅长大规模强一致、高可用(多活 IDC)、高性能、高安全性分布式集群(HAC+HPC)计算;大数据处理,区块链以及人工智能等领域。

13 年以上创业经验,上海重玄科技(philo-tech.com)独立创始人。主要客户包括:
等各大企业。
介绍视频配套幻灯片:技术优势,或者:Technical Advantages(英文版)。

我方所有产品和项目均基于自主研发的跨平台支持环境(技术白皮书)而构建。
白杨应用支撑平台使用汇编、C/C++ 构建,包含数百万行代码和上千个成熟的通用组件。如:单点千万并发量级、集群万亿量级的跨平台网络服务和 Web Service 组件、强一致、抗脑裂(Split Brain)的多活 IDC 高可用(HAC)和高性能(HPC)分布式计算集群技术、高效、高强度的密码编码学组件、布式大数据管理及分析组件等。

全球专利一瞥:我方强一致、高可用、高性能分布式架构和分布式协调等算法均受到多项国家和国际发明专利保护。
支撑平台经过多家 500 强企业实际生产环境以及多个高负载电信、互联网和分布式计算环境十几年验证,其功能、性能和效率均有极高保证。使用久经验证的组件来开发产品不仅可以大大提升产品品质,有效减少产品缺陷,还能够显著提升产品开发效率。
此外,支撑平台还具备很强的可移植性,从大型机、小型机、分布式服务器集群、桌面工作站等传统计算机设备,到 pad、手机、手表、工控设备等嵌入式环境,平台可支持绝大多数主流操作系统和硬件架构。由此,基于白杨应用支撑平台而构建的软件产品先天即具备极高的可移植性。高可移植性不仅可被用于灵活地实现面向不同领域的产品,更可以帮助开发商针对产品的不同生命周期分别选择对应的最佳目标平台。
详见:白杨应用支撑平台技术白皮书,或者:BaiY Application Platform Technical White Paper(英文版)。
多年来,已陆续推出白杨应用支撑平台、白豚 ERP/HRMS 平台、蓝鲸电信计费系统、BYST 安全隧道、高性能、高可用、强一致的多活 IDC 集群解决方案、CDN 3.0 (BYCDN) 解决方案、以及文字防盗版系统等多个完全(100%)由我个人自有的产品和技术方案。欢迎各种合作 :-)
上海交大:计算机科学与技术本科毕业,学士学位。
中学起接触计算机,当时想加入所在中学内的计算机兴趣小组,由于毫无基础被拒。次年自学获得北京市中学生奥林匹克竞赛优胜奖。
大学期间自学通过了 MCP/I 专家和互联网专家、MCSE/I 系统工程师和互联网工程师、MCSD 解决方案开发、MCDBA 数据库管理等全套微软技术资质认证并获得相应证书,并成为了当时中国最年轻的 MCSE。
4 岁起进入中央音乐学院钢琴系学习钢琴、视唱练耳、和声、乐理等,曾在各比赛和演出中多次获奖。从小学到大学一直承担学校各项活动的合唱指挥钢琴伴奏 MIDI 编曲等工作。
钢琴老师为中央音乐学院电子音乐中心(中音公司前身)创始人,我跟着较早地接触了电子音乐和相关设备。有音频处理经验,也曾负责编写音频流处理软件,详见技术白皮书中的 6.1 小节。
自幼喜爱摄影,多次在学校和海淀区摄影比赛中获奖。

BYPSS 是一种强一致、高可用、高性能、大容量的分布式协调国际专利算法。BYPSS 提供了与传统 Paxos/Raft 算法完全相同的一致性和可用性保证,并在此基础上实现了的性能、容量、响应速度、网络利用率等各方面的显著提升。
HAC Manager 作为《白杨应用支撑平台》BYPSS 组件中的配套工具,利用 BYPSS 提供的强一致、高可用和高性能的分布式协调组件,实现了对任意第三方应用(托管服务)的服务选举、故障检测、故障转移和故障恢复等功能:对于竞选相同服务的多个 HAC Manager 实例来说,竞选成功(取得所有权)的节点可以执行用户事先配置的指令来启动相应的托管服务(Service/Daemon);相应地,在失去所有权时,HAC Manager 则会自动停止该托管服务。
HAC Manager 支持对等(多主)和主从(Master / Slave)两种集群模式。在主从模式下,集群检测到Master 节点故障下线时,会启动 Slav e节点上的托管服务来接替其工作(Failover);而当 Master 节点恢复上线后,可配置 Slave 节点是否要将该托管服务的执行权限重新交换给 Master(Failback)。
与此同时,Slave 节点还支持竞选避让机制,可确保在发生网络抖动时尽可能由主节点重新取得托管服务的所有权。避免由于环境微量抖动引起的频繁切换。
配合 BYST、DRBD、HAST、DataKeeper、DFS、Ceph、GlusterFS、Lustre 等分布式存储技术或SAN等共享型存储方案,HAC Manager 的主从模式可以在无需任何修改的前提下,方便地将一个传统的单机服务(如:传统 SQL 数据库、全文搜索引擎、报表生成服务、用户业务逻辑等)转化为强一致、抗脑裂(Split Brain)的跨云、跨 Region 高可用多活 IDC 集群(HAC)。
与主从模式不同,HAC Manager 的对等模式除了可实现强一致的高可用集群(HAC)以外,还能够同时支持分布式高性能计算(HPC)等场景。不过对等模式需要对第三方托管服务进行少量修改才能正常开启。实现方式为:托管服务通过本地回环地址(127.0.0.1)与 HAC Manager 进行通信,在 HAC Manager 的辅助下使用 BYPSS 服务完成服务发现、服务选举、故障检测、故障转移、故障恢复、分布式锁、任务调度,以及消息路由和消息分发等分布式协调作业。此时 HAC Manager 扮演的则是服务网格(Service Mesh)中的 Local Agent 角色(sidecar 模式)。
注:以上所述 BYPSS 算法受我方拥有的国家和国际发明专利保护。
详见:HACMgr 用户手册。
白杨消息端口交换服务(BYPSS):一种基于多数派算法的,强一致(抗脑裂)、高可用的分布式协调组件,可用于向集群提供服务发现、故障检测、服务选举、分布式锁等传统分布式协调服务,同时还支持消息分发与路由等消息中间件功能。由于通过专利算法消除了传统 Paxos/Raft 中的网络广播和磁盘 IO 等主要开销,再加上批量模式支持、并发散列表、高并发服务组件等大量其它优化,使得 BYPSS 可在延迟和吞吐均受限的跨 IDC 网络环境中支持百万节点、万亿端口量级的超大规模计算集群(详见技术白皮书 中的:“5.4.3 消息端口交换服务”等小节)。
带强一致保证的多活 IDC 技术是现代高性能和高可用集群的关键技术,也是业界公认的主要难点。作为实例:2015 年 8 月 20 日 Google GCE 服务中断 12 小时并永久丢失部分数据;2015 年 5 月 27 日、2016 年 7 月 22 及 2019 年 12 月 5 日支付宝多次中断数小时;以及 2013 年 7 月 22 日、2023 年 3 月 29 日微信服务中断数小时等重大事故均属于产品未能实现多活 IDC 架构,单个 IDC 故障导致服务全面下线的惨痛案例。
在上述方面,我方拥有超过十年的积累,掌握多项受国家和国际发明专利保护的分布式架构和算法。得益于这些领先的强一致、高可用、高性能分布式集群算法和架构,我们在蓝鲸、白豚、职业精等全线产品上,均实现了真正的多活 IDC 架构,为客户提供了无以伦比的数据可靠性和服务可用性保证。
分布式协调服务为集群提供服务发现、服务选举、故障检测、故障转移、故障恢复、分布式锁、任务调度,以及消息路由和消息分发等功能。
分布式协调服务是分布式集群的大脑,负责指挥集群中的所有协同工作。将分布式集群协调为一个有机整体,使其有效且一致地运转。实现可线性横向扩展的高性能(HPC)和高可用(HAC)分布式集群系统。
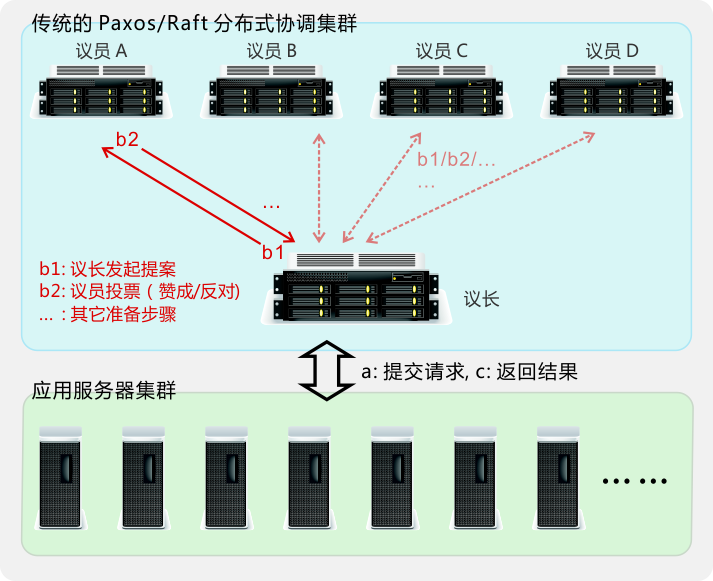
传统的 Paxos/Raft 分布式协调算法为每个请求发起投票,产生至少 2 到 4 次网络广播(b1、b2…)和多次磁盘 IO。使其对网络吞吐和通信时延要求很高,无法部署在跨 IDC(城域网)环境。
我们的专利算法则完全消除了此类开销。因此大大降低了网络负载,显著提升整体效率。并使得集群跨 IDC 部署(多活 IDC)变得简单可行。
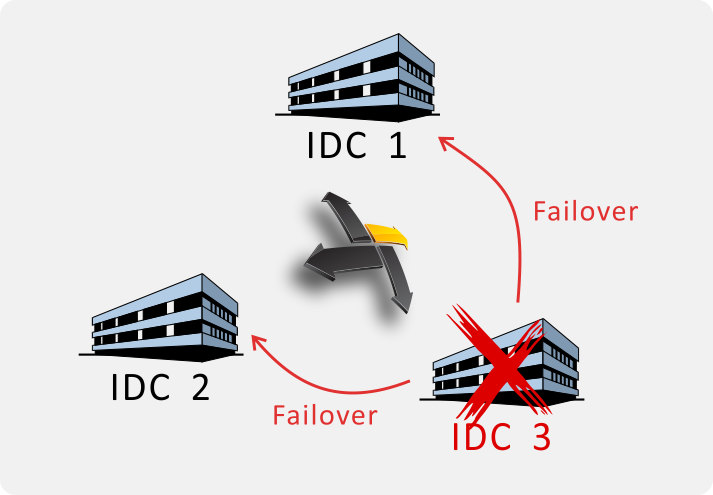
基于我方独有的分布式协调技术,可实现高性能、强一致的多活 IDC 机制。可在毫秒级完成故障检测和故障转移,即使整座 IDC 机房下线,也不会导致系统不可用。同时提供强一致性保证:即使发生了网络分区也不会出现脑裂(Split Brain)等数据不一致的情形。例如:
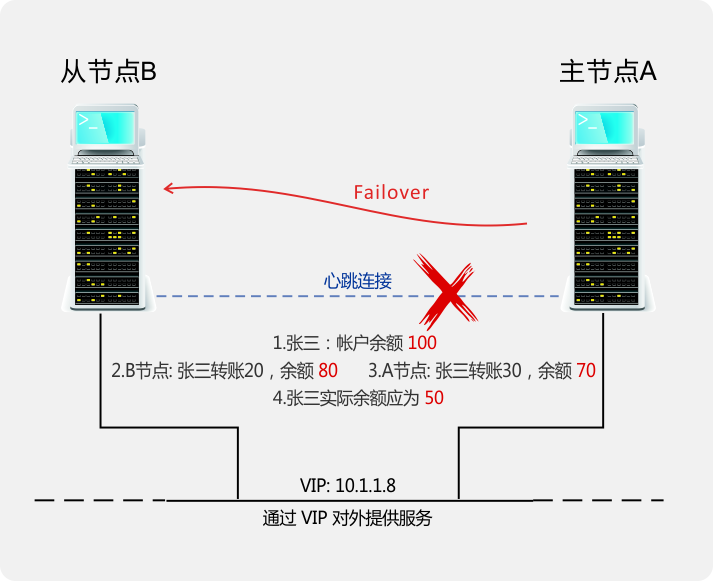
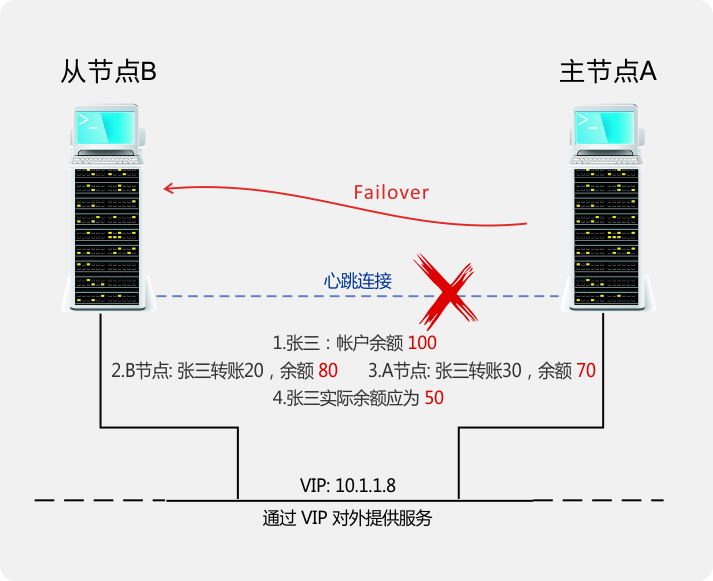
在传统的双机容错方案中,从节点在丢失主节点心跳信号后,会自动将自身提升为主节点,并继续对外提供服务,以实现高可用。在此种情形中,当主从节点均正常,但心跳连接意外断开时(网络分区),就会发脑裂(Split Brain)问题,如上图所示:此时 A、B 均认为对方已下线,故将自己提升为主节点并分别对外提供服务,产生难以恢复的数据不一致。
我方 BYPSS 服务可提供与传统 Paxos/Raft 分布式算法相同水平的强一致性保证,从根本上杜绝脑裂等不一致现象的发生。
类似地:工行、支付宝等服务也有异地容灾方案(支付宝:杭州 -> 深圳、工行:上海 -> 北京)。但在其异地容灾方案中,两座 IDC 之间并无 Paxos 等分布式协调算法保护,因此无法实现强一致,也无法避免脑裂。
举例来说,一个在支付宝成功完成的转账交易,可能要数分钟甚至数小时后才会从杭州主 IDC 被异步地同步到深圳的灾备中心。杭州主 IDC 发生故障后,若切换到灾备中心,意味着这些未同步的交易全部丢失,并伴随大量的不一致。比如:商家明明收到支付宝已收款提示,并且在淘宝交易系统看到买家已付款,并因此发货。但由于灾备中心切换带来的支付宝交易记录丢失,导致在支付宝中丢失了相应的收入,但淘宝仍然提示买家已付款。因此,工行、支付宝等机构在主 IDC 发生重大事故时,宁可停止服务几个小时甚至更久,也不愿意将服务切换到灾备中心。只有在主 IDC 发生大火等毁灭级事故后,运营商才会考虑将业务切换到灾备中心(这也是灾备中心建立的意义所在)。
因此,异地容灾与我方的强一致、高可用、抗脑裂多活 IDC 方案具有本质区别。
此外,Paxos / Raft 在经历过半节点同时故障下线并维修恢复的过程中,无法保证数据的强一致性,可能产生幻读等不一致问题(例如:在一个三节点集群中,节点 A 因为电力故障下线,一小时后节点 B 和 C 则因为磁盘故障下线。此时节点 A 恢复电力供应重新上线,紧接着管理员更换了节点 B 和 C 的磁盘并让它们分别恢复上线。此时整个集群 1 小时内的修改将全部丢失,集群退回到了 1 小时前 A 节点下线时的状态)。而 BYPSS 则从根本上避免了此类问题的发生,因此 BYPSS 拥有比 Paxos / Raft 更强的一致性保证。
由于消除了 Paxos/Raft 算法中的大量广播和分布式磁盘 IO 等高开销环节,配合支撑平台中的高并发网络服务器、以及并发散列表等组件。使得 BYPSS 分布式协调组件除了上述优势外,还提供了更多优秀特性:
批量操作:允许在每个网络包中,同时包含大量分布式协调请求。网络利用率极大提高,从之前的不足 5% 提到到超过 99%。类似于一趟高铁每次只运送一位乘客,与每班次均做满乘客之间的区别。实际测试中,在单千兆网卡上,可实现 400 万次请求每秒的性能。在当前 IDC 主流的双口万兆网卡配置上,可实现8000 万次请求每秒的吞吐。比起受到大量磁盘 IO 和网络广播限制,性能通常不到 200 次请求每秒的 Paxos/Raft 集群,有巨大提升。
超大容量:通常每 10GB 内存可支持至少 1 亿端口。在一台插满 64 根 DIMM 槽的 1U 尺寸入门级 PC Serve 上(8TB),可同时支撑至少 800 亿对象的协调工作;在一台 32U 大型 PC Server 上(96TB),可同时支撑约 1 万亿对象的分布式协调工作。相对地,传统 Paxos/Raft 算法由于其各方面限制,通常只能有效管理和调度数十万对象。
问题的本质在于 Paxos / Raft 等算法中,超过 99.99% 的代价都消耗在了网络广播(投票)和落盘等行为上。而这些行为的目的就是要保证数据的可靠性(数据要同时存储在多数节点的持久化设备上)。而服务发现、服务选举、故障检测、故障转移、故障恢复、分布式锁、任务调度等分布式协调功能所涉及到的恰恰又都是没有长期保存价值的临时性数据。因此花费超过 99.99% 的精力来持久化地保存它们的多个副本是毫无意义的——就算真的发生主节点下线等罕见灾难,我们也可以极高的效率,在瞬间就重新生成这些数据。
就好像张三买了一辆车,这辆车有个附加保险服务,其条款为:在张三万一发生了致命交通意外时,它能提供一种时光倒流机制,将其带回到意外发生之前的一瞬间来避免这场意外的发生。当然,这么牛的服务肯定也很贵,它大概需要预付张三家族在接下来的三生三世里能获得的所有财富。而且即使张三在驾驶这辆车的过程中,始终未发生过致命交通事故,那这些预先支付的服务费也是一分钱都不能减免的。这么昂贵的服务,且不说一般人一生中大概率都不会发生致命交通事故(更别提还要指定具体的某辆车)。即使真发生了,这个三代赤贫的代价也难说就值得吧?
而我们则为自己的汽车产品提供了另一种不同的附加服务:虽然没有时光倒流功能,但我们的服务可以在张三发生致命事故后,将所有受害方全体连车带人瞬间原地满血复活(是一根头发丝都不会少、一块漆皮都不会掉那种满血)。最关键的是,该服务无需预先收取任何费用。张三只需要在每次这样的灾难发生以后,支付相当于其半个月的工资的再生技术服务费就可以了。
综上,我方专利的分布式协调算法,在提供与传统 Paxos/Raft 算法相同等级的强一致性和高可用性保证之同时,极大地降低了系统对网络和磁盘 IO 的依赖,并显著提升了系统整体性能和容量。对于大规模、强一致分布式集群的可用性(HAC)和性能(HPC)等指标均有显著提升。
关于 BYPSS 服务的进一步描述,详见技术白皮书 中的:“5.4.3 消息端口交换服务”等小节。
白杨应用支撑平台使用汇编、C/C++ 构建,包含数百万行代码和上千个成熟的通用组件。平台历经兴业银行(China CIB)、中石油(CNPC)、华安保险(Sinosafe Insurance)、淘宝网(taobao.com)、易果网(yiguo.com)、烟台万华集团、法国兴业银行(SOCIETE GENERALE)、中国农业银行(ABC)、宝马集团(BMW)、陕汽集团(陕汽重卡)、德尔福汽车(Delphi)、美联航(United Airlines)、GE(美国通用电气)、贝塔斯曼(Bertelsmann)、埃森哲(Accenture)、光大银行(CEB)、壹基金(One Foundation)、中国宋庆龄基金会、中国移动(China Mobile)、中国联通(China Unicom)、国家电网(SGCC)等多家 500 强企业实际生产环境以及多个高负载电信、互联网和分布式计算环境十几年验证。支持各主流操作系统和硬件平台。
白杨应用支撑平台全球专利一瞥
当前支持的操作系统主要包括:
当前支持的主要硬件平台包括:x86/x64、ARM、IA64、MIPS、RISC-V、POWER、SPARC 等。
详见:白杨应用支撑平台。



















